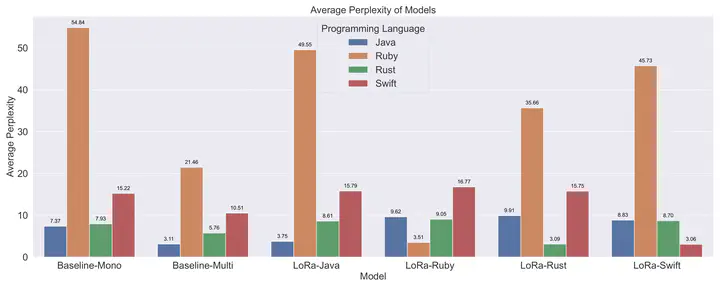
 Perplexity of fine-tuned models
Perplexity of fine-tuned modelsThe democratisation of AI and access to code language models have become pivotal goals in the field of artificial intelligence. Large Language Models (LLMs) have shown exceptional capabilities in code intelligence tasks, but their accessibility remains a challenge due to computational costs and training complexities. This paper addresses these challenges by presenting a comprehensive approach to scaling down Code Intelligence LLMs. To enhance usability, we focus on training smaller code language models, which lowers the computation cost of inference and training. We extend these models to diverse programming languages, enabling code completion tasks across various domains
Additionally, we explore the impact of different choices in fine-tuning LLMs, providing empirical evidence on training efficiency in terms of time, cost, and performance. In pursuit of these goals, we fine-tune a Python-based mono-lingual code LLM for Java, Rust, Ruby, and Swift. Utilising the LoRa Parameter Efficient Fine-Tuning technique, we share these models, their training datasets, and evaluation results openly. Extensive hyperparameter tuning, trade-off analysis, and error analysis shed light on the effects of training process choices. This work contributes to the democratisation of AI by making Code LLMs more accessible and usable for practitioners. By addressing computational barriers and providing insights into training dynamics, we bridge the gap between AI development and practical application, fostering an environment where code intelligence tools can be readily adopted.
Ammar عمار
Machine Learning Engineer
My research interests include Multi-Modal Machine Learning, Generative Models, and Multilingual NLP.