Biography
I’m an AI and machine learning engineer with a passion for driving real-world impact through responsible innovation. NLP and efficient large language models are my specialties – I love democratizing software creation through my work. I’m currently pursuing a MSc in AI, researching efficient fine-tuning of transformers for code generation. In my roles so far, I’ve applied ML to agriculture, NLP, and software engineering challenges. Outside of work, I’m fascinated by the societal implications of AI and actively explore issues like algorithmic bias and responsible ML. I love connecting with fellow researchers pushing the boundaries of AI for good. When I’m not coding, you can find me in the cinema or on the football pitch. I’m always eager to take on new challenges and collaborate with thoughtful teams to advance the equitable use of AI.
- Multi-Modal Machine Learning
- Multilingual NLP
- Responsible AI
- Geospatial Analysis
MSc in Artificial Intelligence, 2022
University of Edinburgh
BSc in Electrical and Electronic Engineering - Software Engineering, 2014
University of Khartoum
Skills
90%
100%
10%
Experience

Projects
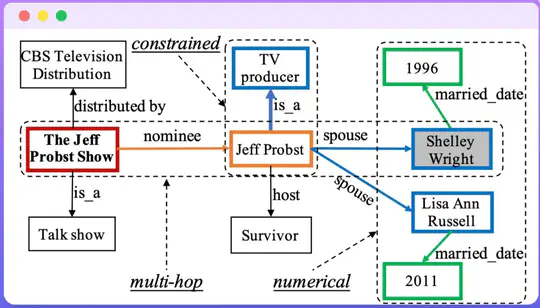

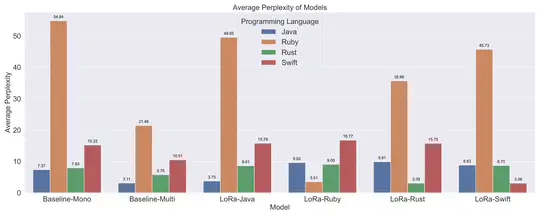


Featured Publications

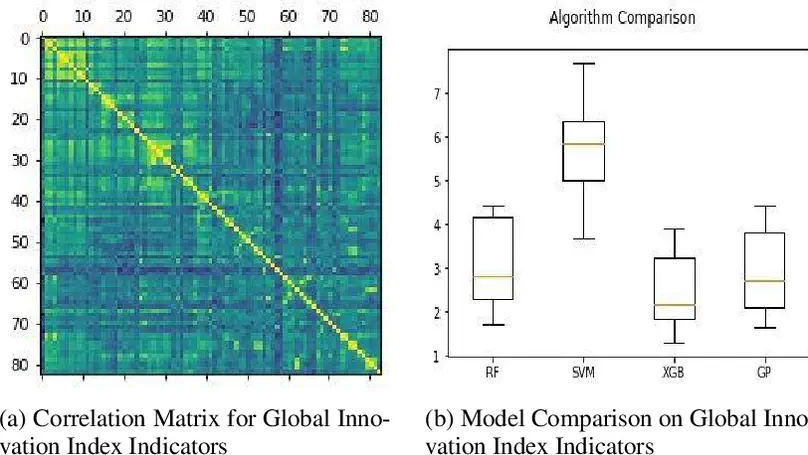

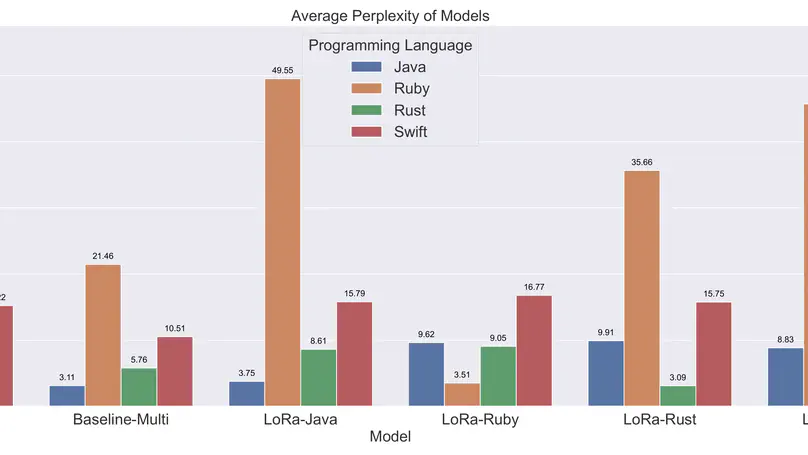

Contact
Send me a message and I’ll get back to you as soon as possible.